Telecom Churn Predictor
Introduction
Customer churn occurs when customers stop doing business with a company. Understanding the reasons behind customer churn is important as it is less expensive for companies to maintain existing customers then it is to attract new customers. This project will present a customer churn prediction model using Telecom Customer Churn dataset. Relevant and irrelevant variables will be determined, along with what model works best for the customer churn analysis with the given dataset. Supervised learning model with a categorical target variable.
#Import libraries required for this project
import numpy as np
import pandas as pd
#Import visualization libraries
import seaborn as sns
import matplotlib.pyplot as plt
#Display notebooks
%matplotlib inline
#Import machine learning libraries
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix,accuracy_score,classification_report
from sklearn.metrics import roc_auc_score,roc_curve,scorer
from sklearn.metrics import f1_score
import statsmodels.api as sm
from sklearn.metrics import precision_score,recall_score
from imblearn.over_sampling import SMOTE
#Hide warnings in the pink box
import warnings
warnings.filterwarnings("ignore")
Exploratory Analysis
After importing the required libraries I want to bring in the dataset as a dataframe using Pandas. I then want to view the first several rows of the dataframe to get an idea of the feature names, corresponding data values, and missing data if any.
#Create a DataFrame with telecom data set
telecom_df=pd.read_csv("WA_Fn-UseC_-Telco-Customer-Churn.csv")
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
#Display the first 15 rows of the dataframe
telecom_df.head(15)
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | Yes | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | No | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | Yes | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | No | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | No | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
| 5 | 9305-CDSKC | Female | 0 | No | No | 8 | Yes | Yes | Fiber optic | No | No | Yes | No | Yes | Yes | Month-to-month | Yes | Electronic check | 99.65 | 820.5 | Yes |
| 6 | 1452-KIOVK | Male | 0 | No | Yes | 22 | Yes | Yes | Fiber optic | No | Yes | No | No | Yes | No | Month-to-month | Yes | Credit card (automatic) | 89.10 | 1949.4 | No |
| 7 | 6713-OKOMC | Female | 0 | No | No | 10 | No | No phone service | DSL | Yes | No | No | No | No | No | Month-to-month | No | Mailed check | 29.75 | 301.9 | No |
| 8 | 7892-POOKP | Female | 0 | Yes | No | 28 | Yes | Yes | Fiber optic | No | No | Yes | Yes | Yes | Yes | Month-to-month | Yes | Electronic check | 104.80 | 3046.05 | Yes |
| 9 | 6388-TABGU | Male | 0 | No | Yes | 62 | Yes | No | DSL | Yes | Yes | No | No | No | No | One year | No | Bank transfer (automatic) | 56.15 | 3487.95 | No |
| 10 | 9763-GRSKD | Male | 0 | Yes | Yes | 13 | Yes | No | DSL | Yes | No | No | No | No | No | Month-to-month | Yes | Mailed check | 49.95 | 587.45 | No |
| 11 | 7469-LKBCI | Male | 0 | No | No | 16 | Yes | No | No | No internet service | No internet service | No internet service | No internet service | No internet service | No internet service | Two year | No | Credit card (automatic) | 18.95 | 326.8 | No |
| 12 | 8091-TTVAX | Male | 0 | Yes | No | 58 | Yes | Yes | Fiber optic | No | No | Yes | No | Yes | Yes | One year | No | Credit card (automatic) | 100.35 | 5681.1 | No |
| 13 | 0280-XJGEX | Male | 0 | No | No | 49 | Yes | Yes | Fiber optic | No | Yes | Yes | No | Yes | Yes | Month-to-month | Yes | Bank transfer (automatic) | 103.70 | 5036.3 | Yes |
| 14 | 5129-JLPIS | Male | 0 | No | No | 25 | Yes | No | Fiber optic | Yes | No | Yes | Yes | Yes | Yes | Month-to-month | Yes | Electronic check | 105.50 | 2686.05 | No |
Looking over the first 15 rows of data, the features make sense in terms of characteristics for a telecom customer. The values correspond to the features. Many features are categorical and missing data doesn’t seem like a problem for the data set. For the categorial columns: OnlineSecurity, OnlineBackup, DeviceProtection, TechSupport, StreamingTV, and StreamingMovies the “No internet service” value will be changed to “No” for 6 features: “OnlineSecurity”, “OnlineBackup”, “DeviceProtection”, “TechSupport”, “StreamingTV”, “StreamingMovies”. The “Churn” feature is the target variable.
#Changing "No internet service" value to "No" for select features
select_features = ["OnlineSecurity", "OnlineBackup","DeviceProtection","TechSupport","StreamingTV", "StreamingMovies"]
for x in select_features:
telecom_df[x] = telecom_df[x].replace({"No internet service" : "No" })
#Display number of observations, number of features, data types of features, feature names
telecom_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
customerID 7043 non-null object
gender 7043 non-null object
SeniorCitizen 7043 non-null int64
Partner 7043 non-null object
Dependents 7043 non-null object
tenure 7043 non-null int64
PhoneService 7043 non-null object
MultipleLines 7043 non-null object
InternetService 7043 non-null object
OnlineSecurity 7043 non-null object
OnlineBackup 7043 non-null object
DeviceProtection 7043 non-null object
TechSupport 7043 non-null object
StreamingTV 7043 non-null object
StreamingMovies 7043 non-null object
Contract 7043 non-null object
PaperlessBilling 7043 non-null object
PaymentMethod 7043 non-null object
MonthlyCharges 7043 non-null float64
TotalCharges 7043 non-null object
Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB
The telecom data set has 7043 observations and 21 features, of these features 18 are string, 2 are integer, and one is floating point data type. The “TotalCharges” feature has an incorrect data type of string, data type should be floating point. The “SeniorCitizen” feature is a binary column where values need to change from 1 or 0 to “Yes” or “No”. The “Tenure” feature will be condensed to 5 groups: “0-12 Month”, “12-24 Month”, “24-48 Month”, “48-60 Month”, and “>60 Month”.
#Changing data type for TotalCharges from string to float coerce option fills in NaN for missing values
telecom_df["TotalCharges"] = pd.to_numeric(telecom_df["TotalCharges"], errors = "coerce")
#Verify the data type for TotalCharges feature
telecom_df["TotalCharges"].dtype
dtype('float64')
#Changing data type for "SeniorCitizen" feature from integer to object
telecom_df["SeniorCitizen"] = telecom_df["SeniorCitizen"].astype("object")
#Changing values for "SeniorCitizen" from 1 or 0 to "Yes" or "No"
telecom_df["SeniorCitizen"]=telecom_df["SeniorCitizen"].replace({1:"Yes",0:"No"})
#Create groups for "tenure" data type
def group_tenure(telecom):
if telecom["tenure"] <= 12:
return "0-12 Months"
elif(telecom["tenure"] > 12 ) & (telecom["tenure"] <= 24):
return "12-24 Months"
elif(telecom["tenure"] > 24) & (telecom["tenure"] <= 48):
return "24-48 Months"
elif(telecom["tenure"] > 48) & (telecom["tenure"] <= 60):
return "48-60 Months"
elif telecom["tenure"]>60:
return "60+ Months"
#Create feature "Tenure Group" and apply group_tenure function
telecom_df["Tenure Group"] = telecom_df.apply(lambda telecom_df: group_tenure(telecom_df),
axis=1)
Dropping tenure and customerID featues. Tenure feature is no longer needed as Tenure Group has been created. Customer ID does not contain useful information for target variable Churn.
#Dropping features "tenure" and "customerID"
#Dropping "tenure" because it is not needed we created categorical feature "Tenure Group"
#Removing the columns from the dataframe
telecom_df.drop(["tenure","customerID"],axis=1, inplace=True)
#Give sum for each feature of all NaN values
telecom_df.isnull().sum()
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
MonthlyCharges 0
TotalCharges 11
Churn 0
Tenure Group 0
dtype: int64
#Inserting 0 for NaN values in TotalCharges feature, specifying inplace=True so it affects the dataframe.
telecom_df["TotalCharges"].fillna(value=0, inplace=True)
Missing Data
Since this dataset contains missing data, I have changed the values to 0 for “TotalCharges” instead of deleting the rows. There are different ways to approach missing values such as inserting the mean, median, or deleting rows with missings values. I am inserting 0 because deleting the 11 rows with NaN will take away important information. There should be an understanding of why data is missing before determining how to handle the missing data.
#Display the number unique values for all features
telecom_df.nunique()
gender 2
SeniorCitizen 2
Partner 2
Dependents 2
PhoneService 2
MultipleLines 3
InternetService 3
OnlineSecurity 2
OnlineBackup 2
DeviceProtection 2
TechSupport 2
StreamingTV 2
StreamingMovies 2
Contract 3
PaperlessBilling 2
PaymentMethod 4
MonthlyCharges 1585
TotalCharges 6531
Churn 2
Tenure Group 5
dtype: int64
#Plot distributions of numerical features
telecom_df.hist()
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x000001A6C1CD0EF0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x000001A6C1EA9E80>]],
dtype=object)
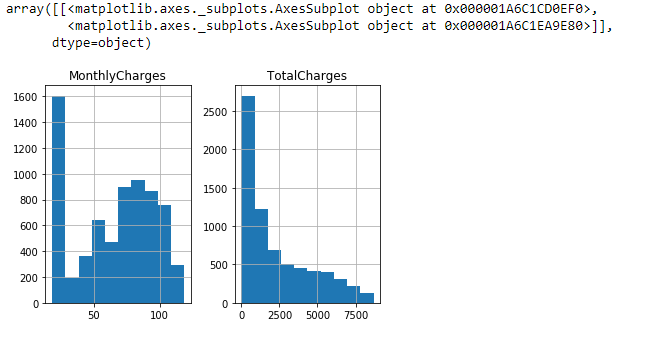
The distribution for “MonthlyCharges” shows a high frequency with lowest charges and a low frequency with high charges. The “TotalCharges” distribution is skewed to the right. The distributions do not seem uncommon and the boundaries make sense.
#Correlation between TotalCharges feature and MonthlyCharges
telecom_df["TotalCharges"].corr(telecom_df["MonthlyCharges"])
0.6511738315787841
MonthlyCharges and TotalCharges are correlated, therefore TotalCharges will be dropped. I’m choosing to keep MonthlyCharges because the data is original. I did not insert 0s for missing values like I did with TotalCharges.
#Dropping features "TotalCharges" because of its correlation with "MonthlyCharges"
#Removing the columns from the dataframe
telecom_df.drop(["TotalCharges"],axis=1, inplace=True)
#Creating a list of all categorical features
categorical_features = telecom_df.nunique()[telecom_df.nunique()< 6].keys().tolist()
#Displaying distributions of categorical features to understand the unique values for features
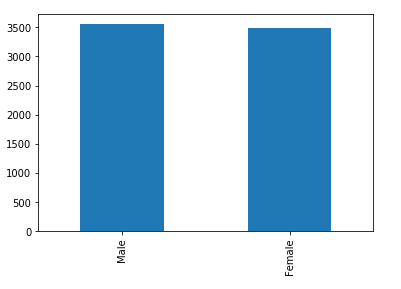
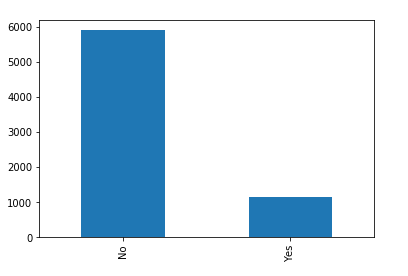
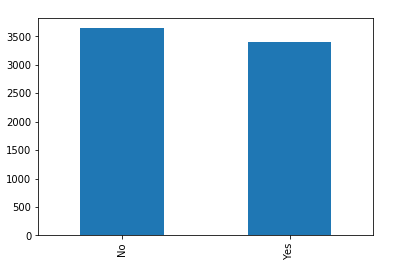
for x in categorical_features:
print("Feature:",x)
telecom_df[x].value_counts().plot(kind="bar")
plt.show()
Feature: gender
Feature: SeniorCitizen
Feature: Partner
Feature: Dependents
Feature: PhoneService
Feature: MultipleLines
Feature: InternetService
Feature: OnlineSecurity
Feature: OnlineBackup
Feature: DeviceProtection
Feature: TechSupport
Feature: StreamingTV
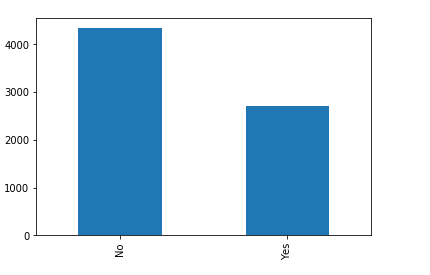
Feature: StreamingMovies
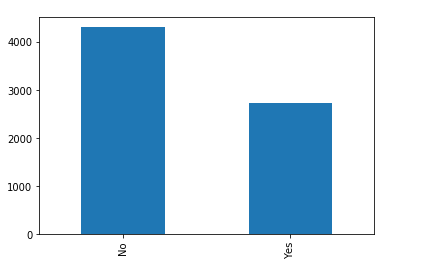
Feature: Contract
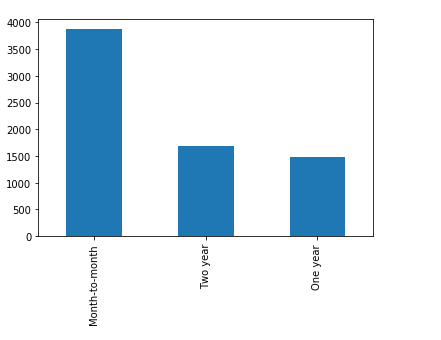
Feature: PaperlessBilling
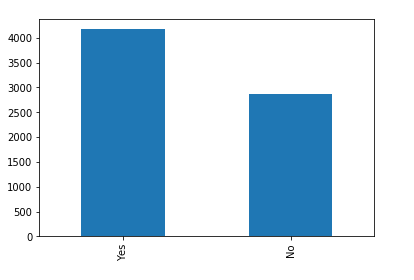
Feature: PaymentMethod
Feature: Churn
Feature: Tenure Group
The categorical feature distributions above show the unique values for each feature, there are no incorrect values. All of the categorical features seem to have a reasonably broad distribution, as a result, all of them will be kept for further analysis.
sns.barplot(x="Tenure Group", y="MonthlyCharges", hue="Churn", data=telecom_df)
<matplotlib.axes._subplots.AxesSubplot at 0x1a6c34578d0>
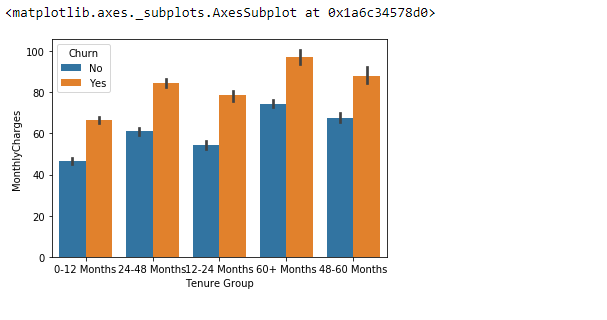
The bar plot above shows that across all tenure groups customers who churn have higher monthly charges then those that do not churn.
sns.barplot(x="PaymentMethod",y="MonthlyCharges", hue="Churn", data=telecom_df)
plt.xticks(rotation=30)
(array([0, 1, 2, 3]), <a list of 4 Text xticklabel objects>)
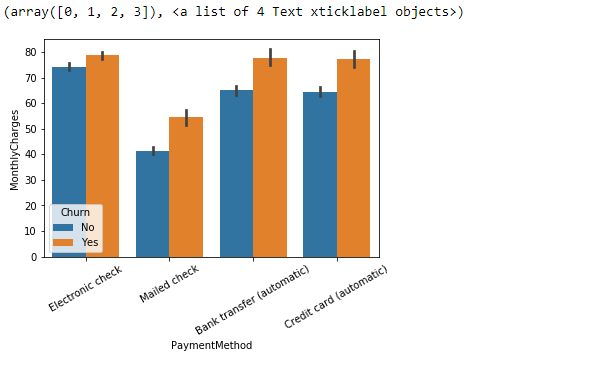
The bar plot above shows once again that customers who churn have higher monthly charges no matter what payment method they are using.
#Display summary statistics for "MonthlyCharges" feature 'yes' Churn values
telecom_df[telecom_df["Churn"]=="Yes"].describe()
| MonthlyCharges | |
|---|---|
| count | 1869.000000 |
| mean | 74.441332 |
| std | 24.666053 |
| min | 18.850000 |
| 25% | 56.150000 |
| 50% | 79.650000 |
| 75% | 94.200000 |
| max | 118.350000 |
#Display summary statistics for "MonthlyCharges" feature 'no' Churn values
telecom_df[telecom_df["Churn"]=="No"].describe()
| MonthlyCharges | |
|---|---|
| count | 5174.000000 |
| mean | 61.265124 |
| std | 31.092648 |
| min | 18.250000 |
| 25% | 25.100000 |
| 50% | 64.425000 |
| 75% | 88.400000 |
| max | 118.750000 |
The summary statistics above for the target variable churn shows there are significantly more “No” churn than “Yes” churn. Also, “Yes” churn has a higher mean, lower standard deviation, higher first quartile/mean/third quartile. Both “No” and “Yes” churn have similar min/max values.
sns.boxplot(x=telecom_df["Churn"], y=telecom_df["MonthlyCharges"])
<matplotlib.axes._subplots.AxesSubplot at 0x1a6c3605e10>
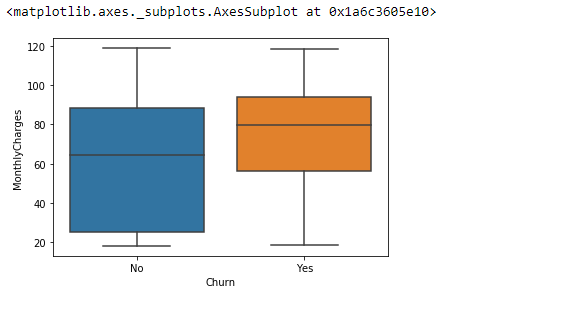
As observed with the bar plots and summary statistics the box plot above also shows customer’s who have churned have a higher median MonthlyCharges, first quartile, and third quartile than non-churned customers.
Data Preprocessing
In this section categorical columns will be encoded and numerical columns will be scaled this will help when running the data on models.
#Displaying number of unique values for columns in order to encode
telecom_df.nunique()
gender 2
SeniorCitizen 2
Partner 2
Dependents 2
PhoneService 2
MultipleLines 3
InternetService 3
OnlineSecurity 2
OnlineBackup 2
DeviceProtection 2
TechSupport 2
StreamingTV 2
StreamingMovies 2
Contract 3
PaperlessBilling 2
PaymentMethod 4
MonthlyCharges 1585
Churn 2
Tenure Group 5
dtype: int64
#Target column
target_var = ["Churn"]
#Categorical features
cat_features = telecom_df.nunique()[telecom_df.nunique() < 6].keys().tolist()
cat_features = [x for x in cat_features if x not in target_var]
#Numerical features
numerical_features = ["MonthlyCharges"]
#Binary features with 2 values
binary_features = telecom_df.nunique()[telecom_df.nunique()==2].keys().tolist()
#Features with more than 2 values
multi_features = [x for x in cat_features if x not in binary_features]
#Label encoding binary features
label_enc = LabelEncoder()
for i in binary_features:
telecom_df[i] = label_enc.fit_transform(telecom_df[i])
#Creating dummie values for features with multiple values
telecom_df = pd.get_dummies(data=telecom_df,columns = multi_features)
#Scaling numerical columns
standard = StandardScaler()
scale = standard.fit_transform(telecom_df[numerical_features])
scale = pd.DataFrame(scale, columns=numerical_features)
#Dropping numerical feature "MonthlyCharges" and merging scaled values
telecom_df = telecom_df.drop(["MonthlyCharges"], axis = 1)
telecom_df = telecom_df.merge(scale, left_index=True, right_index=True, how="left")
Model Building
Base Model
In this section logistic regression will be used as a baseline model which other models will be compared against. Logistic regression is a good baseline model as it is a simple yet powerful algorithm that can be easily implemented. This is a binary logistic regression, where the outcome can be ‘yes’ or ‘no’ coded as 1 or 0.
#Splitting data, typical test size is between 30%-20%
train, test = train_test_split(telecom_df, test_size=.25, random_state=111)
ind_cols = [i for i in telecom_df.columns if i not in target_var]
#Seperating independent columns and dependent column
train_X = train[ind_cols]
train_Y = train[target_var]
test_X = test[ind_cols]
test_Y = test[target_var]
#Make an instance of the model, please note using default parameters for model
logisticRegr = LogisticRegression()
logisticRegr.fit(train_X,train_Y)
predictions = logisticRegr.predict(test_X)
probabilities = logisticRegr.predict_proba(test_X)
coefficients = pd.DataFrame(logisticRegr.coef_.ravel())
column_df = pd.DataFrame(ind_cols)
coef_sumry = (pd.merge(column_df, coefficients, left_index=True, right_index=True, how="left"))
coef_sumry.columns = [ "features", "coefficients" ]
coef_sumry = coef_sumry.sort_values(by="coefficients", ascending=False)
print(logisticRegr)
print("\n Classification report: \n", classification_report(test_Y, predictions))
print("Accuracy Score: ",accuracy_score(test_Y,predictions))
conf_matrix = confusion_matrix(test_Y,predictions)
model_roc_auc = roc_auc_score(test_Y, predictions)
print("Area under curve: ", model_roc_auc, "\n")
print(coef_sumry)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
Classification report:
precision recall f1-score support
0 0.85 0.90 0.88 1327
1 0.63 0.53 0.58 434
accuracy 0.81 1761
macro avg 0.74 0.71 0.73 1761
weighted avg 0.80 0.81 0.80 1761
Accuracy Score: 0.807495741056218
Area under curve: 0.7141103420973125
features coefficients
25 Tenure Group_0-12 Months 0.996873
18 Contract_Month-to-month 0.572086
30 MonthlyCharges 0.425144
11 PaperlessBilling 0.327166
16 InternetService_Fiber optic 0.318476
10 StreamingMovies 0.228712
1 SeniorCitizen 0.112762
9 StreamingTV 0.094153
23 PaymentMethod_Electronic check 0.077147
26 Tenure Group_12-24 Months 0.035247
0 gender 0.019016
2 Partner -0.009797
7 DeviceProtection -0.114782
19 Contract_One year -0.156305
13 MultipleLines_No phone service -0.161146
14 MultipleLines_Yes -0.165837
3 Dependents -0.208123
21 PaymentMethod_Bank transfer (automatic) -0.213926
24 PaymentMethod_Mailed check -0.237921
6 OnlineBackup -0.246922
27 Tenure Group_24-48 Months -0.259116
22 PaymentMethod_Credit card (automatic) -0.272099
8 TechSupport -0.279104
15 InternetService_DSL -0.297711
12 MultipleLines_No -0.319816
5 OnlineSecurity -0.395222
4 PhoneService -0.485653
28 Tenure Group_48-60 Months -0.531890
17 InternetService_No -0.667564
29 Tenure Group_60+ Months -0.887914
20 Contract_Two year -1.062580
Assessing the predictive ability of the Logistic Regression model:
The classification report shows results for the prdictions from the model.
Precision for 0 ‘no’ is 0.85 and 1 ‘yes’ is 0.63. Precision shows how close the model’s predictions are to the observed values. The precision for 0 is higher than 1, hopefully the prcision will improve with other models.
Recall for 0 ‘no’ is 0.90 and 1 ‘yes’ is 0.53. Recall measures the proportion of actual positives that are correctly identified as such. Precision was low for ‘yes’ so it would maked sense that recall would be low as well.
f1-score for 0 ‘no’ is 0.88 and 1 ‘yes’ is 0.58. F1-score is the harmonic mean of precision and recall.
Accuracy Score is 0.807. Accuracy describes overall, how often the model is correct.
Area under curve is 0.714. Area under curve gives the rate of successful classification by the logistic model.
As mentioned earlier this dataset contains a large number of actual negatives compared to actual positives.
Feature analysis:
The top three most relevant features include Tenure Group_0-12 Months, Contract_Month-to-month, and MonthlyCharges.
Synthetic Minority Oversampling Technique (SMOTE)
Synthetic Minority Oversampling Technique will be used to tackle the issue of an unequal balance of actual negatives to actual positives in the classification category.
ind_cols = [i for i in telecom_df.columns if i not in target_var]
smt_X = telecom_df[ind_cols]
smt_Y = telecom_df[target_var]
#Split train and test data
smt_train_X,smt_test_X,smt_train_Y,smt_test_Y = train_test_split(smt_X,smt_Y, test_size = .25, random_state = 111)
#Oversampling minority class using smote
ovs = SMOTE(random_state = 0)
ovs_smt_X,ovs_smt_Y = ovs.fit_sample(smt_train_X,smt_train_Y)
ovs_smt_X = pd.DataFrame(data = ovs_smt_X,columns=ind_cols)
ovs_smt_Y = pd.DataFrame(data = ovs_smt_Y,columns=target_var)
logistic_smote = LogisticRegression()
logistic_smote.fit(ovs_smt_X,ovs_smt_Y)
predictions = logistic_smote.predict(test_X)
probabilities = logistic_smote.predict_proba(test_X)
coefficients = pd.DataFrame(logistic_smote.coef_.ravel())
column_df = pd.DataFrame(ind_cols)
coef_sumry = (pd.merge(column_df, coefficients, left_index=True, right_index=True, how="left"))
coef_sumry.columns = [ "features", "coefficients" ]
coef_sumry = coef_sumry.sort_values(by="coefficients", ascending=False)
print(logistic_smote)
print("\n Classification report: \n", classification_report(test_Y, predictions))
print("Accuracy Score: ", accuracy_score(test_Y,predictions))
conf_matrix = confusion_matrix(test_Y, predictions)
print("Area under curve: ", model_roc_auc,"\n")
print(coef_sumry)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
Classification report:
precision recall f1-score support
0 0.92 0.72 0.81 1327
1 0.48 0.81 0.61 434
accuracy 0.74 1761
macro avg 0.70 0.76 0.71 1761
weighted avg 0.81 0.74 0.76 1761
Accuracy Score: 0.7399204997160704
Area under curve: 0.7141103420973125
features coefficients
25 Tenure Group_0-12 Months 1.198356
18 Contract_Month-to-month 0.704495
16 InternetService_Fiber optic 0.444345
11 PaperlessBilling 0.394848
30 MonthlyCharges 0.366681
10 StreamingMovies 0.325993
23 PaymentMethod_Electronic check 0.183353
9 StreamingTV 0.152339
0 gender 0.020780
26 Tenure Group_12-24 Months 0.018308
2 Partner 0.009374
14 MultipleLines_Yes -0.046439
13 MultipleLines_No phone service -0.057104
1 SeniorCitizen -0.070945
19 Contract_One year -0.080640
7 DeviceProtection -0.124014
21 PaymentMethod_Bank transfer (automatic) -0.129148
15 InternetService_DSL -0.169271
22 PaymentMethod_Credit card (automatic) -0.181353
27 Tenure Group_24-48 Months -0.241221
24 PaymentMethod_Mailed check -0.247559
12 MultipleLines_No -0.271163
6 OnlineBackup -0.272461
8 TechSupport -0.283959
3 Dependents -0.286180
4 PhoneService -0.317602
5 OnlineSecurity -0.398608
28 Tenure Group_48-60 Months -0.494223
17 InternetService_No -0.649780
29 Tenure Group_60+ Months -0.855926
20 Contract_Two year -0.998562
Assessing the predictive ability of SMOTE:
The results show recall for 1 ‘yes’ improved to 0.81 from 0.53 but precision decreased from 0.63 to 0.48. However, accuracy decreased from 0.80 to 0.74. This model has a lot of trade offs to improve the recall score.
Feature analysis:
For SMOTE the top three most relevant features include Tenure Group_0-12 Months, Contract_Month-to-month, and InternetService_Fiber optic.
Recursive Feature Elimination
Recursive Feature Elimination (RFE) recursively removes weak features, builds a model using the remaining features and calculates model accuracy. RFE repeatedly constructs a model and chooses the best performing feature, setting the feature aside and then repeating the process with the rest of the features. The goal of RFE is to select features by recursively considering smaller and smaller sets of features, thus eliminating dependencies and collinearity.
from sklearn.feature_selection import RFE
logr = LogisticRegression()
rfe = RFE(logr,10)
rfe = rfe.fit(ovs_smt_X,ovs_smt_Y.values.ravel())
rfe.support_
rfe.ranking_
array([20, 17, 22, 8, 13, 1, 11, 15, 10, 9, 1, 1, 7, 18, 19, 1, 1,
1, 1, 16, 1, 4, 3, 12, 2, 1, 21, 6, 5, 1, 14])
#identified columns Recursive Feature Elimination
idc_rfe = pd.DataFrame({"rfe_support" :rfe.support_,
"columns" : [i for i in telecom_df.columns if i not in target_var],
"ranking" : rfe.ranking_,
})
ind_cols = idc_rfe[idc_rfe["rfe_support"] == True]["columns"].tolist()
#Split train and test data
train_rf_X = ovs_smt_X[ind_cols]
train_rf_Y = ovs_smt_Y
test_rf_X = test[ind_cols]
test_rf_Y = test[target_var]
logistic_rfe = LogisticRegression()
logistic_rfe.fit(train_rf_X,train_rf_Y)
predictions = logistic_rfe.predict(test_rf_X)
probabilities = logistic_rfe.predict_proba(test_rf_X)
coefficients = pd.DataFrame(logistic_rfe.coef_.ravel())
column_df = pd.DataFrame(ind_cols)
coef_sumry = (pd.merge(column_df, coefficients, left_index=True, right_index=True, how="left"))
coef_sumry.columns = [ "features", "coefficients" ]
coef_sumry = coef_sumry.sort_values(by="coefficients", ascending=False)
print(logistic_rfe)
print("\n Classification report: \n", classification_report(test_rf_Y, predictions))
print("Accuracy Score: ", accuracy_score(test_rf_Y,predictions))
conf_matrix = confusion_matrix(test_rf_Y, predictions)
print("Area under curve: ", model_roc_auc,"\n")
print(coef_sumry)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
Classification report:
precision recall f1-score support
0 0.93 0.68 0.78 1327
1 0.46 0.83 0.59 434
accuracy 0.72 1761
macro avg 0.69 0.76 0.69 1761
weighted avg 0.81 0.72 0.74 1761
Accuracy Score: 0.7177739920499716
Area under curve: 0.7141103420973125
features coefficients
8 Tenure Group_0-12 Months 1.330217
6 Contract_Month-to-month 1.032522
1 StreamingMovies 0.551391
4 InternetService_Fiber optic 0.520720
2 PaperlessBilling 0.456932
0 OnlineSecurity -0.420573
3 InternetService_DSL -0.509966
9 Tenure Group_60+ Months -0.622179
7 Contract_Two year -0.982969
5 InternetService_No -1.400288
Assessing the predictive ability of RFE:
RFE is in the same range as the other two models. The accuracy score is the lowest.
Feature analysis:
For RFE the top three most relevant features include Tenure Group_0-12 Months, Contract_Month-to-month, and StreamingMovies.
Summary:
From the results above, Logistic Regression, SMOTE, and RFE can be used for churn analysis with this dataset. However, Logistic Regression does have a higher accuracy then the other two.
I have learned the following through the analysis:
There doesn’t seem to be a relationship between gender and churn.
Customers with a month to month contract within 12 months and on paperless billing are more likely to churn. Customers who have 5 years plus tenure with a 2 year contract and not using paperless billing are less likely to churn.
Features such as tenure group, internet service, contract, monthly charges, and paperless billing contribute to customer churn.