Movie Recommender
Introduction
This is an unsupervised classification project using different datasets from movielens. A movie recommender helps customers save time by giving them movie recommendations instead of the customer investing a lot of time looking through dozens of movies hoping to find a movie they think they might like. This project will focus on collaborative filtering using k-Nearest Neighbor and Matrix Factorization with Singular Value Decomposition (SVD).
Exploratory Data Analysis
This section will give information about the datasets such as number of rows/columns, the data types for columns, and display a sample of the data from the two data frames. We will find missing values,reshape data frames, and display graphs of the data.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
from sklearn.decomposition import TruncatedSVD
import warnings
warnings.filterwarnings("ignore", category=RuntimeWarning)
#Create a dataframe from the movies dataset
movies_df = pd.read_csv("movies.csv")
#Display first 5 rows of dataframe
movies_df.head()
| movieId | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 1 | 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
#Removing year from title feature
movietitle = movies_df["title"].str.rsplit(" ", n=1, expand=True)
movies_df["title"] = movietitle[0]
movies_df.head()
| movieId | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story | Adventure|Animation|Children|Comedy|Fantasy |
| 1 | 2 | Jumanji | Adventure|Children|Fantasy |
| 2 | 3 | Grumpier Old Men | Comedy|Romance |
| 3 | 4 | Waiting to Exhale | Comedy|Drama|Romance |
| 4 | 5 | Father of the Bride Part II | Comedy |
#Display number of rows, columns for the movies dataframe
movies_df.shape
(9742, 3)
#Display data types of columns, row counts, names of columns
movies_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9742 entries, 0 to 9741
Data columns (total 3 columns):
movieId 9742 non-null int64
title 9742 non-null object
genres 9742 non-null object
dtypes: int64(1), object(2)
memory usage: 228.4+ KB
#Display columns with the sum of missing values for movies dataframe
movies_df.isnull().sum()
movieId 0
title 0
genres 0
dtype: int64
#Create a dataframe from the ratings movie dataset
ratings_df = pd.read_csv("ratings.csv")
#Display first 5 rows of dataframe
ratings_df.head()
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
| 4 | 1 | 50 | 5.0 | 964982931 |
#Display number of rows, columns for the ratings dataframe
ratings_df.shape
(100836, 4)
#Display data types of columns, row counts, names of columns
ratings_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100836 entries, 0 to 100835
Data columns (total 4 columns):
userId 100836 non-null int64
movieId 100836 non-null int64
rating 100836 non-null float64
timestamp 100836 non-null int64
dtypes: float64(1), int64(3)
memory usage: 3.1 MB
#Display columns with the sum of missing values for ratings dataframe
ratings_df.isnull().sum()
userId 0
movieId 0
rating 0
timestamp 0
dtype: int64
#Merge dataframes ratings_df and movies_df
movie_ratings_combine = movies_df.merge(ratings_df, on = "movieId")
#Drop timestamp and genres columns from movie_ratings_combine dataframe
columns = ["timestamp","genres"]
movie_ratings_combine = movie_ratings_combine.drop(columns, axis=1)
movie_ratings_combine.head()
| movieId | title | userId | rating | |
|---|---|---|---|---|
| 0 | 1 | Toy Story | 1 | 4.0 |
| 1 | 1 | Toy Story | 5 | 4.0 |
| 2 | 1 | Toy Story | 7 | 4.5 |
| 3 | 1 | Toy Story | 15 | 2.5 |
| 4 | 1 | Toy Story | 17 | 4.5 |
#Display distribution of ratings
sns.set_style("whitegrid")
sns.distplot(movie_ratings_combine["rating"], kde=False)
<matplotlib.axes._subplots.AxesSubplot at 0x16c6ca4edd8>
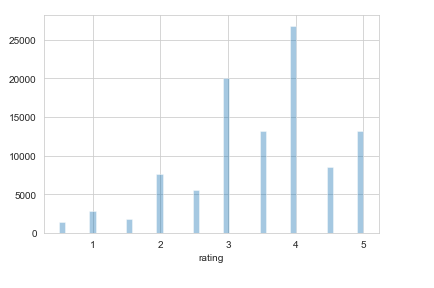
The ratings distribution above shows ratings ranging from 0.5 to 5.0. The most common rating is 4.0 and least common is 0.5.
#Creating a dataframe that includes rating count for each movie
movie_ratingcount = (movie_ratings_combine.groupby(by=["title"])["rating"].count().reset_index().
rename(columns={"rating":"ratingtotal_count"})
[["title","ratingtotal_count"]])
movie_ratingcount.head()
| title | ratingtotal_count | |
|---|---|---|
| 0 | '71 | 1 |
| 1 | 'Hellboy': The Seeds of Creation | 1 |
| 2 | 'Round Midnight | 2 |
| 3 | 'Salem's Lot | 1 |
| 4 | 'Til There Was You | 2 |
#Merge total ratings count with ratings which will give us a dataframe with ratings and total rating counts for movies
ratingcount_ratings = movie_ratings_combine.merge(movie_ratingcount, left_on="title", right_on="title", how = "left")
ratingcount_ratings.head()
| movieId | title | userId | rating | ratingtotal_count | |
|---|---|---|---|---|---|
| 0 | 1 | Toy Story | 1 | 4.0 | 215 |
| 1 | 1 | Toy Story | 5 | 4.0 | 215 |
| 2 | 1 | Toy Story | 7 | 4.5 | 215 |
| 3 | 1 | Toy Story | 15 | 2.5 | 215 |
| 4 | 1 | Toy Story | 17 | 4.5 | 215 |
#Movies with the most ratings
highestcount_ratings = ratingcount_ratings.sort_values("ratingtotal_count", ascending = False).drop_duplicates("movieId")
highestcount_ratings.head()
| movieId | title | userId | rating | ratingtotal_count | |
|---|---|---|---|---|---|
| 10346 | 356 | Forrest Gump | 609 | 4.0 | 329 |
| 8757 | 318 | Shawshank Redemption, The | 202 | 4.0 | 317 |
| 7998 | 296 | Pulp Fiction | 261 | 5.0 | 307 |
| 16415 | 593 | Silence of the Lambs, The | 414 | 4.0 | 279 |
| 45071 | 2571 | Matrix, The | 125 | 5.0 | 278 |
#Visualization for movies with most ratings count
plt.figure(figsize=(12,4))
plt.bar(highestcount_ratings["title"].head(5),highestcount_ratings["ratingtotal_count"].head(5))
<BarContainer object of 5 artists>
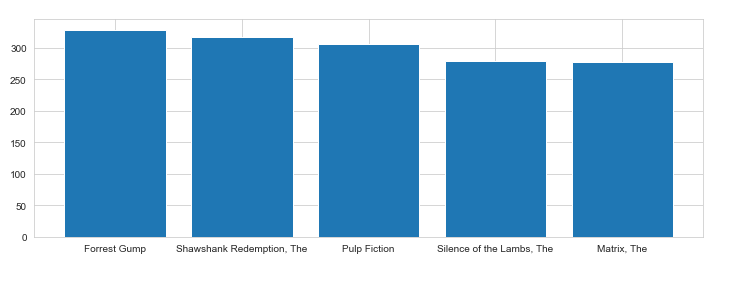
Figure: shows movies with the most ratings count
ratingcount_ratings.head()
| movieId | title | userId | rating | ratingtotal_count | |
|---|---|---|---|---|---|
| 0 | 1 | Toy Story | 1 | 4.0 | 215 |
| 1 | 1 | Toy Story | 5 | 4.0 | 215 |
| 2 | 1 | Toy Story | 7 | 4.5 | 215 |
| 3 | 1 | Toy Story | 15 | 2.5 | 215 |
| 4 | 1 | Toy Story | 17 | 4.5 | 215 |
Collaborative Filtering
In this section we determine recommendations by calculating the similiarities between movies using ratings. Users who have liked similar movies can be recommended movies liked by those same users or similar users. There will be a memory based approach with k-Nearest Neighbors and a model based technique with matrix factorization. Memory based is nonparametric machine learning where algorithms do not make strong assumptions about the form of the data. Model based is parametric machine learning that makes assumptions about the data by determining a known form.
k-Nearest Neighbors
Memory based approach k-NN is an algorithm that makes predictions based on the k most similar training patterns for each data point, in this case the ratings vector. The method does not assume anything other than patterns that are close are likely to have a similar output variable.
In order to apply k-NN the table needs to be changed to a 2D matrix, and missing values filled with zeros as we are calculating the distance between rating vectors. Since this matrix will contain a high percentage of zeros the scipy sparse matrix will be used for more efficient calculations.
#Drop duplicates, create pivot with title as index, create sparse matrix
ratingcount_ratings = ratingcount_ratings.drop_duplicates(["userId","title"])
ratingcount_ratings_pivot = ratingcount_ratings.pivot(index="title", columns="userId", values="rating").fillna(0)
ratingcount_ratings_matrix = csr_matrix(ratingcount_ratings_pivot.values)
The unsupervised algorithm used to calculate nearest neighbor is brute-force search, and metric cosine is used in order to have the algorithm calculate the cosine similarities between rating vectors.
knn_model = NearestNeighbors( metric='cosine', algorithm='brute')
knn_model.fit(ratingcount_ratings_matrix)
NearestNeighbors(algorithm='brute', leaf_size=30, metric='cosine',
metric_params=None, n_jobs=1, n_neighbors=5, p=2, radius=1.0)
#Find nearest neighbors and picks the most popular
pickmovie_title = np.random.choice(ratingcount_ratings_pivot.shape[0])
dist,ind = knn_model.kneighbors(ratingcount_ratings_pivot.iloc[pickmovie_title, :].values.reshape(1,-1),n_neighbors=7)
#For loop to retrieve movies within a short distance of a randomly chosen movie
for i in range(0,len(dist.flatten())):
if i == 0:
print("Recommendations for {0}:\n".format(ratingcount_ratings_pivot.index[pickmovie_title]))
else:
print("{0}: {1}, with distance of {2}:".format(i,ratingcount_ratings_pivot.index[ind.flatten()[i]],
dist.flatten()[i]))
Recommendations for Out of the Past:
1: Gilda, with distance of 0.19053433856666202:
2: Place in the Sun, A, with distance of 0.2305471023299399:
3: Written on the Wind, with distance of 0.23212314121718625:
4: Butcher Boy, The, with distance of 0.2374780028516814:
5: Whole Wide World, The, with distance of 0.24156266715692443:
6: Reds, with distance of 0.2440228969502266:
The k-Nearest Neighbors algorithm provided popular neighbors to movie Out of the Past. The distance between Out of the Past and neighboring movie is provided in the output.
Singular Value Decomposition (SVD)
Model based matrix factorization using singular value decomposition is a matrix decomposition method for reducing a matrix into three matrices. Data is assumed the form of a matrix reduced to three matrices. Singular value decomposition will capture features that can be used to compare movies in relation to users.
SVD will require a 2D matrix, utility matrix, filled with zeros for missing values.
#Create pivot with userId as index
ratingcount_ratings_pivot2 = ratingcount_ratings.pivot(index="userId", columns="title", values="rating").fillna(0)
ratingcount_ratings_pivot2.head()
| title | '71 | 'Hellboy': The Seeds of Creation | 'Round Midnight | 'Salem's Lot | 'Til There Was You | 'Tis the Season for Love | 'burbs, The | 'night Mother | (500) Days of Summer | *batteries not included | ... | Zulu | [REC] | [REC]² | [REC]³ 3 Génesis | anohana: The Flower We Saw That Day - The Movie | eXistenZ | xXx | xXx: State of the Union | ¡Three Amigos! | À nous la liberté (Freedom for Us) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| userId | |||||||||||||||||||||
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 4.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 9446 columns
The utility matrix is then transposed where movie titles change to rows and userId change to columns.
#Transpose matrix
X=ratingcount_ratings_pivot2.values.T
The dataframe columns are compressed to 24 latent variables, n_components=24. The new data dimensions are 9446x24.
#Fit transpose utility matrix into the model
SVD = TruncatedSVD( n_components=24, random_state=18)
matrix = SVD.fit_transform(X)
Pearson’s R correlation coeffecient are calculated for every movie pair in the matrix.
corr = np.corrcoef(matrix)
corr.shape
(9446, 9446)
#Pick movie from k-NN to compare results
movie_title = ratingcount_ratings_pivot2.columns
movietitle_list = list(movie_title)
test_movietitle = movietitle_list.index("Out of the Past")
print(test_movietitle)
6201
corr_test_movietitle = corr[test_movietitle]
#List movies that have high correlation coefficients
list(movie_title[(corr_test_movietitle<1.0)&(corr_test_movietitle>0.9)])
['All That Heaven Allows',
'Born Yesterday',
'Buddy Holly Story, The',
'East of Eden',
'Enchanted April',
'Great Santini, The',
'House of Mirth, The',
'Jagged Edge',
'Lady Eve, The',
'Little Voice',
'Luzhin Defence, The',
'Marty',
'Matewan',
'Minus Man, The',
'Mister Roberts',
'My Man Godfrey',
'Out of the Past',
'Place in the Sun, A',
'Reds',
'Shall We Dance? (Shall We Dansu?)',
'South Pacific',
'Sweet Smell of Success',
'Tender Mercies',
'Umbrellas of Cherbourg, The (Parapluies de Cherbourg, Les)',
'Whole Wide World, The',
'Written on the Wind',
'Year of Living Dangerously, The']
The above list of recommended movies include some movies from the k-Nearest Neighbors list. More movies are provided as a range from 1.00 to 0.90 for correlation coefficient was used to determine which movies to recommend.